Apache Kafka
Apache Kafka is a distributed event store and stream-processing platform. It is an open-source system developed by the Apache Software Foundation. The platform can be used for real-time data pipelines, integration, stream processing, and more. This is a cheat sheet style overview of the main architecture of Apache Kafka.
 HINT: If you're viewing this on a desktop browser, right click the above image and "open in new tab" for an un-scaled view.
HINT: If you're viewing this on a desktop browser, right click the above image and "open in new tab" for an un-scaled view.
Architecture - Main points
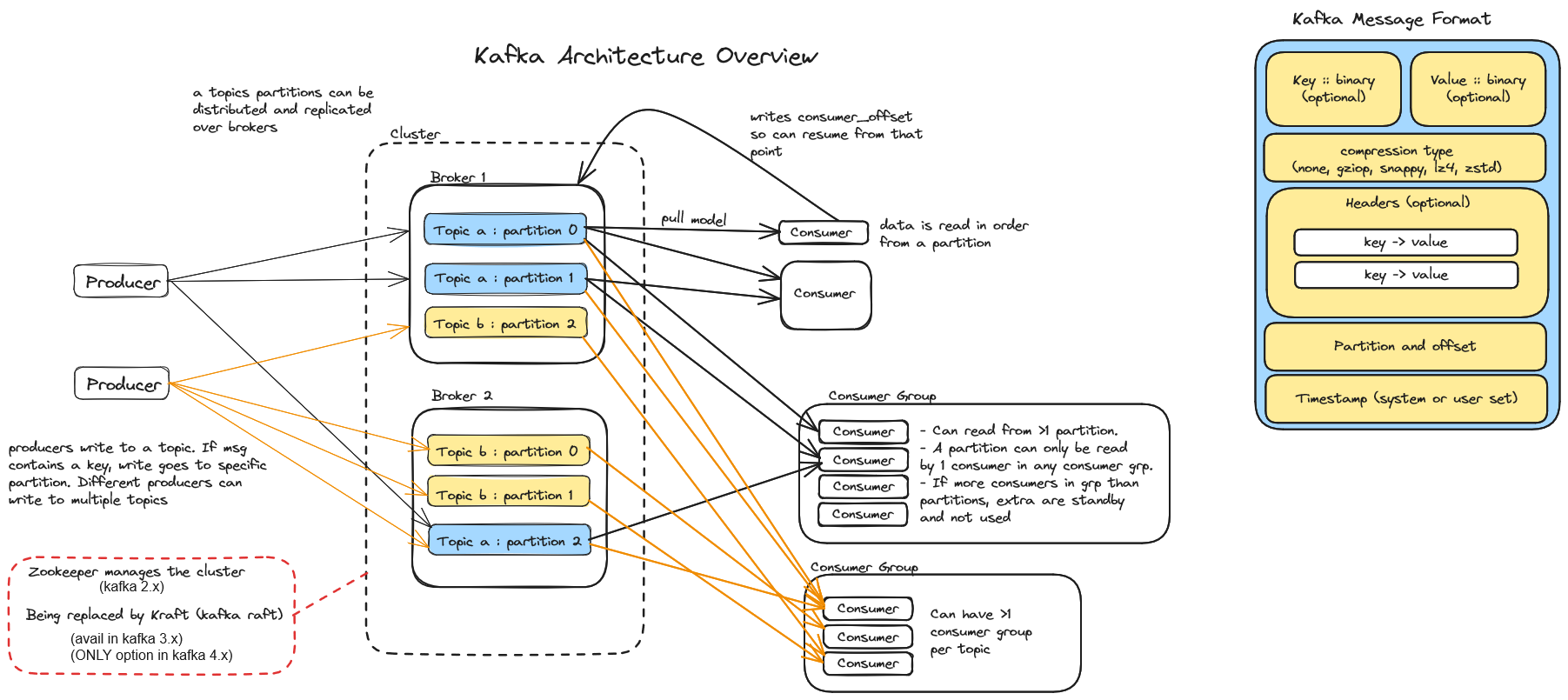
A Kafka cluster has many brokers and topics. The cluster is managed by zookeeper upto Kafka version 3.x, but is being replaced by Kraft (Kafka Raft), which will be the only option from version 4.x.
A topic is a stream of data, similar to a table in a database. Topics can be distributed and replicated across different brokers.
Kafka producers send data to a topic.
Kafka consumers read data from a topic. Data is read in order from a partition. Consumers can be grouped into a consumer group for performance. In a consumer group, a partition can only be read by one consumer, a consumer can read from more than one partition, therefore you may end up with spare capacity of consumers in a consumer group. More than one consumer or consumer group can read from the same topic or partition.
Topics are split into partitions. If your messages include a key, it's guaranteed that all message of the same key will be in the same partition. This means a Kafka partition could be used to implement the thread delegate pattern, except when you repartition!
Data written to a partition is immutable (cannot be changed), but is only kept for a defined amount of time (default of 1 week).
The order of messages is only guaranteed within a partition (so you may need to choose your message keys carefully).
Without a key, messages are assigned to a random partition in a round-robin fashion.
For production use, a replication factor or 3 is recommended
Outbox pattern
You can use the outbox pattern with Kafka to prevent double writes, and/or for speed. This batches messages in memory. If an instance goes down, messages in memory will be lost. Therefore for transactional messages (orders, trades etc), you can set the batch size to 1 to prevent loss. This mitigates the chance of loosing messages, but is single threaded so not really a true outbox pattern any more.
Apache Pulsar
In Kafka, serving (consumption) and storage of messages are coupled. For example if you need to scale out the number of brokers to be able to serve messages at a higher rate, then you also scale out the storage too.
Apache Pulsar separates message storage and message serving. It uses a broker to serve messages, and a bookie (bookkeeper) for the storage. This layered architectural approach addresses the coupling of storage and serving in Kafka.